NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базе

В рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями.
Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.

Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800.
Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с.
И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса.
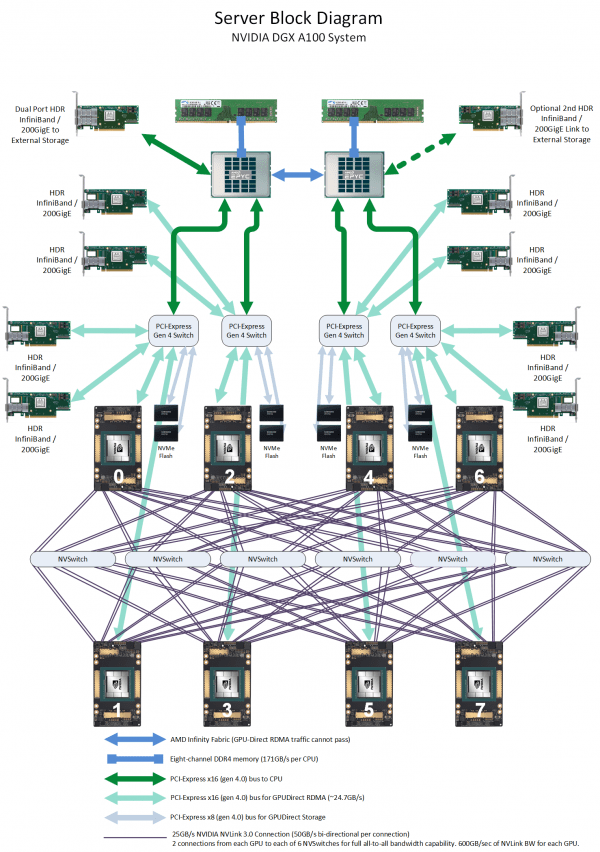
Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется.

Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.

Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования.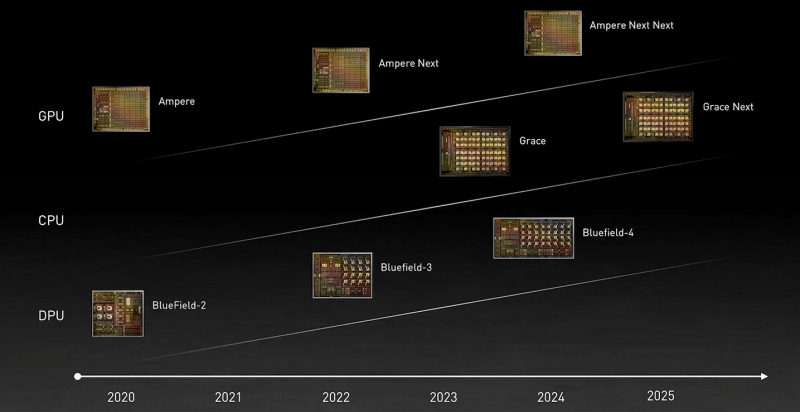
В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.

Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.